Welcome To HybridQRA.
A workflow that utilizes RAG technology, allowing AI models to retrieve and generate answers based on your own data, ensuring accuracy and relevance
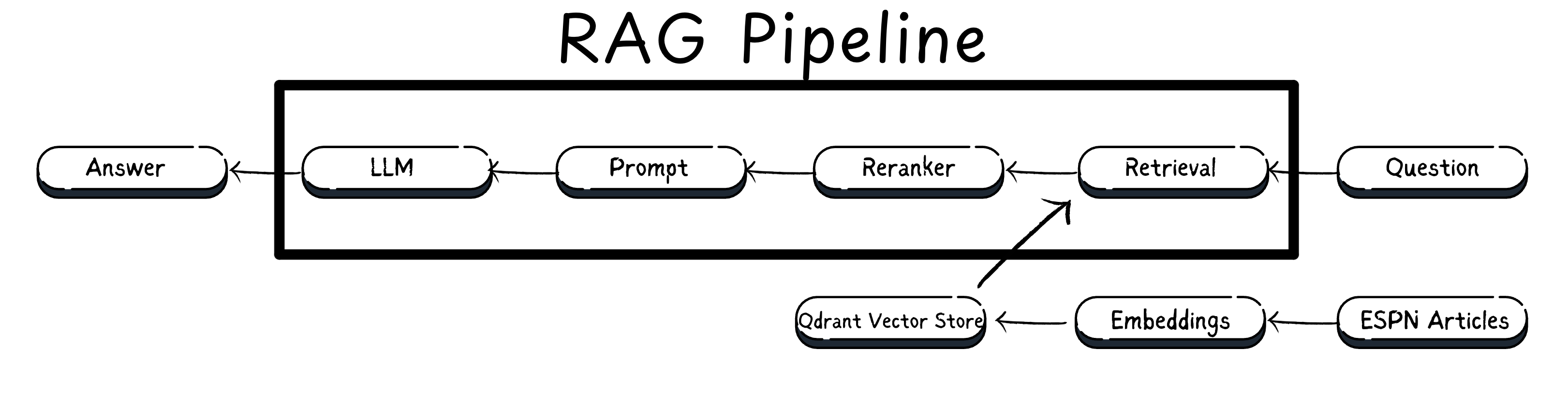
The Project's Tech Stack
RAG 101
Why Use RAG?
Imagine this: You’re working with an undocumented API, a contract, or new data. You use ChatGPT or another language model, but it can’t give you reliable answers because it wasn’t trained on that specific data.
As a result, you have to spend a lot of time and effort searching through various sources to find the answers to your questions, even though the answers should be simple. This happens because regular AI models can’t handle your task.
RAG is a technology that solves this problem.
How Does It Work?
Your data is split into smaller documents (for example, each paragraph becomes a separate document). These documents are then turned into embeddings, which capture their meaning and key words.
The embeddings are stored in a vector database (like Qdrant), which organizes the data for quick retrieval.
When you ask a question, the vector database finds the most relevant paragraphs and sends them along with your query to the language model, allowing it to generate an accurate answer based on the data it received.
Project Overview
About HybridQRA
HybridQRA is a Retrieval-Augmented Generation (RAG) engine that leverages the Qdrant vector database to enable hybrid search, combining both dense vectors (based on semantic similarity) and sparse vectors (based on keyword search).
To answer a given question, the vector database is queried to retrieve the most relevant contexts from the documents. These contexts are then re-ranked using Cohere's "rerank-v3.5" model, and only the highest-ranking paragraph is forwarded to the large language model (LLM) for precise and accurate question-answering.
The entire project, including the website and chat UI, was containerized using Docker and deployed on AWS.
Check Source Code
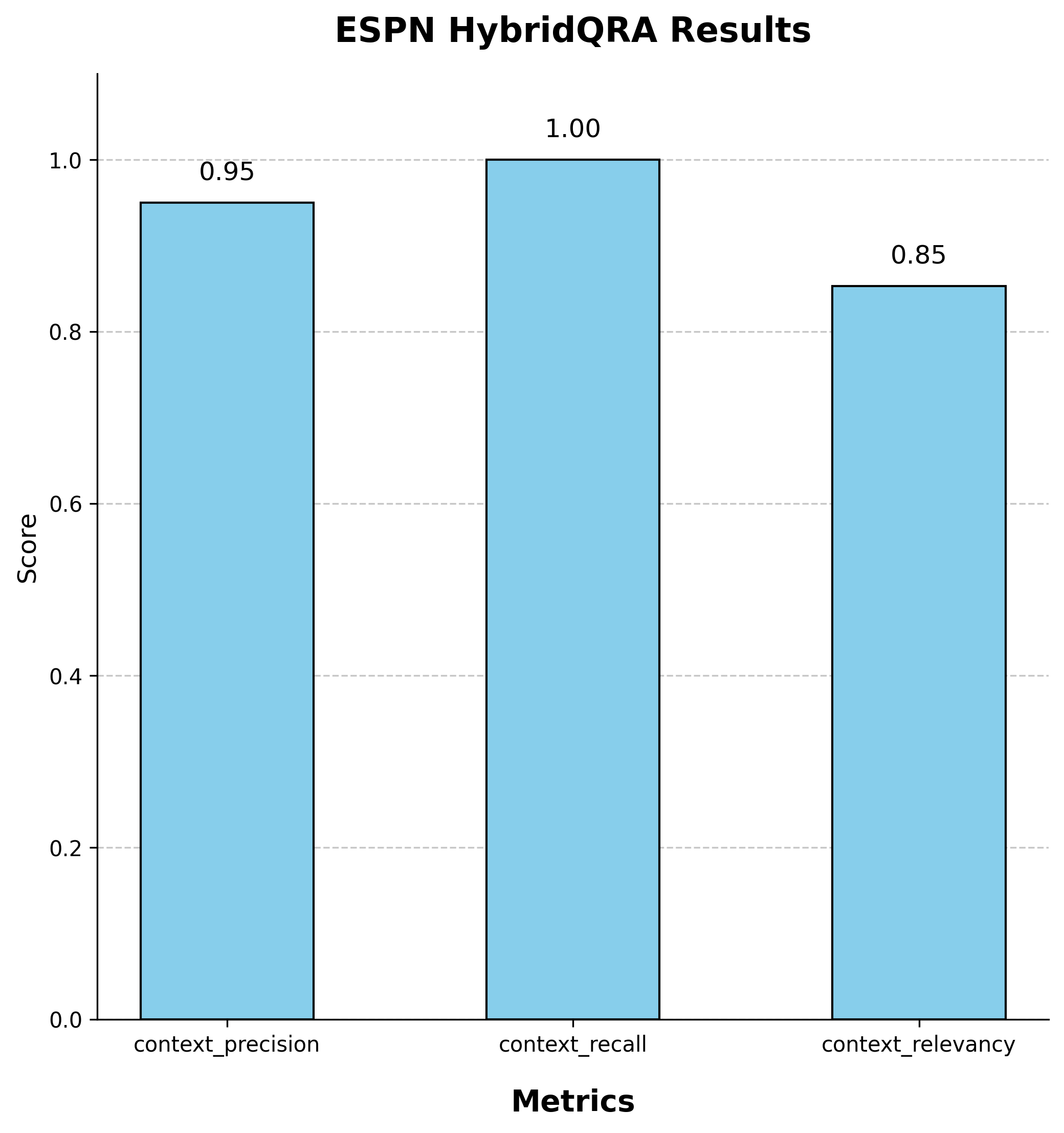
Evaluation With ESPN Articles
An automated script was developed using Selenium to scrape articles from the ESPN website, one of the world's largest sports platforms, extracting article text (organized by paragraphs) along with various metadata attributes. The data was filtered and stored in a pandas DataFrame, ensuring that only relevant, sports-related information was retained.
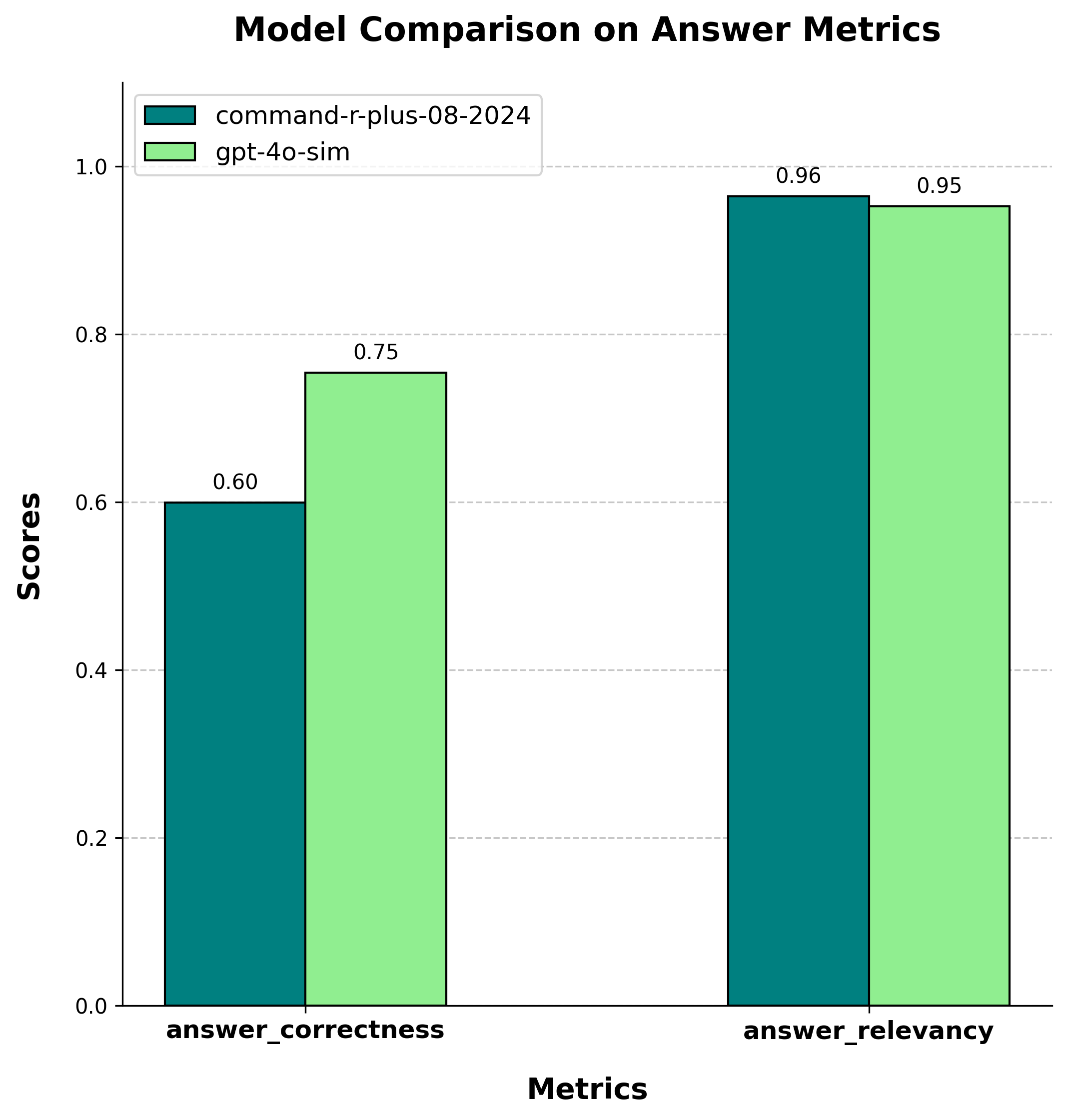
The test set for this project was a synthetic dataset generated from the articles using RAGAS. Below are the evaluation results of HybridQRA's performance based on RAGAS metrics, alongside a comparison of Cohere's "command-r-plus-08-2024" and OpenAI's "gpt-4o-sim" models in terms of their capabilities.
It is important to note that HybridQRA is responsible solely for retrieving and ranking the most relevant contexts, while the LLM model determines the final answer's relevance and correctness. The quality of the response is influenced by both components—HybridQRA ensures that the model receives high-quality context, but the ultimate accuracy and coherence of the answer depend on the LLM's reasoning and generation capabilities.
It is important to note that HybridQRA is responsible solely for retrieving and ranking the most relevant contexts, while the LLM model determines the final answer's relevance and correctness. The quality of the response is influenced by both components—HybridQRA ensures that the model receives high-quality context, but the ultimate accuracy and coherence of the answer depend on the LLM's reasoning and generation capabilities.
Try HybridQRA
Ask Your Questions!
Try HybridQRA with a demo collection of ESPN articles—the very set it was tested on.
Example questions:
1. Why was Tatum anxious about becoming a father?
2. How did Brad Stevens help Tacko Fall?
1. Why was Tatum anxious about becoming a father?
2. How did Brad Stevens help Tacko Fall?
Please note: the chat interface can answer only questions about the content in this collection, and due to API usage limits, each user is restricted to 5 prompts per session.
Generate Questions Using Claude
Follow these two simple steps to generate questions for the HybridQRA chat.
1. Download the "ESPN_articles" CSV
First, download the ESPN_articles CSV file.
To avoid exceeding the LLM's length limit, the file includes only the first 100 paragraphs from the collection's articles.
2. Upload it to Claude and generate questions
Upload the file to Claude and ask it to generate questions based on the "Paragraph_text" column. Feel free to create your own questions as well!
Example prompt: Please generate 5 questions that can only be answered using the data from the 'paragraph_text' column in the provided file, the other columns contain metadata about the text in the 'paragraph_text' column. These questions can require information from more than one paragraph.
About me
Hello everyone! I'm Alon Cohen, a Python developer specializing in data engineering, AI, and data analysis. Feel free to reach out to me for job opportunities!
My knowledge includes Python, HTML, CSS, SQL, and various APIs and frameworks such as Pandas, Selenium and LangChain. I have experience working with data pipelines, ETL processes, and orchestration tools like Apache Airflow, as well as cloud services like AWS, ensuring efficient data flow and management.
